Д. Хузет 1, М. Х. Джаббар 1,2, О. Хаммами 2
1 Лаборатория GIPSA, Гренобль. 2 ENSTA ParisTech, Париж, Франция
Аннотация :
В этой статье мы описываем процесс проектирования, архитектуру и реализацию нашего 3D-мультипроцессора с NoC. Конструкция, основанная на 16 процессорах, обменивающихся данными с использованием сетки NoC 4x2x2, распределенной по двум уровням, подробно обсуждается и будет изготовлена с использованием технологии Tezzaron с 130-нм стандартной библиотекой Global Foundaries с низким энергопотреблением. Целью данной работы является точное измерение производительности NoC в реальном 3D-чипе при запуске мобильных мультимедийных приложений для оценки влияния 3D-архитектуры по сравнению с 2D.
ВВЕДЕНИЕ
Что касается перехода на субнанометровый транзистор, дизайн очень сложный. 3D-интеграция рассматривается как альтернатива для увеличения плотности транзисторов, чтобы соответствовать высокопроизводительному дизайну, не сталкиваясь со многими проблемами, как видно при масштабировании CMOS. Устанавливая матрицы или пластины, мы можем повысить производительность, поскольку общая длина провода уменьшается, а также энергопотребление. Укладка нескольких кристаллов также уменьшит общую площадь чипа, что делает его очень подходящим для мобильных устройств. Тем не менее, некоторые проблемы, такие как термическая обработка и тестирование 3D-архитектур, должны быть преодолены, прежде чем 3D-технологии могут быть внедрены в потребительских устройствах [1].
II. СВЯЗАННЫХ С РАБОТОЙ
За последние несколько лет было изучено много вопросов в архитектуре и дизайне 2D NoC, таких как процесс проектирования, оценка реализации и освоение пространства проектирования [2] [3] [4] [5]. Тем не менее, оценка архитектуры 3D NoC ограничена, так как технология все еще активно исследуется многими организациями.
Несмотря на то, что оценка производительности 3D-архитектуры была проведена с использованием моделирования [6] [7] [8], все еще существует необходимость в реальной реализации 3D-архитектуры для точного измерения производительности, а также для проверки результатов моделирования. Несколько 3D-архитектур были разработаны и изготовлены ранее. Т. Чжан и др. Разработали архитектуру SoC в 3D для приложения H.264 с использованием технологии Tezzaron [9]. Хили и др. Изготовили многопроцессорную архитектуру, состоящую из 64 ядер с памятью инструкций в одном слое и памятью SRAM 256 КБ в другом слое. Архитектура на основе буфера используется для межпроцессорной связи [10]. Van Der Plas и др., Loi и др. И Mineo и др. Также продемонстрировали 3D-архитектуру, ориентированную на архитектуру NoC [11] [12] [13]. Их работа была сосредоточена на демонстрации использования TSV для сигнализации между матрицами, а также характеристики TSV, что не является нашей целью в этой работе.
Наша цель состоит в том, чтобы спроектировать 3D-многопроцессорный чип с 3D-архитектурой NoC, распределенной по нескольким уровням (два здесь), и измерить производительность при запуске приложений, прежде всего для оценки связи NoC в реальной 3D-архитектуре. Это также делается для проверки симуляции параллельных приложений в 3D NoC-архитектуре. Проект будет отправлен на изготовление через CMP [14].
III. МАРШРУТИЗИРОВАННАЯ АРХИТЕКТУРА
Архитектура маршрутизатора имеет тип буферизации ввода, как показано на рисунке 1. Он имеет 4 соседних порта, один вертикальный порт для подключения к другому уровню и один локальный порт для процессора. Сетевой интерфейс, показанный на рисунке 2, соединяет процессор с маршрутизатором через порт FIFO. Основываясь на адресе данных и количестве слов, которые должны быть включены в пакет, сетевой интерфейс будет обращаться к памяти данных процессоров для обработки блоков данных через DMA. Каждый блок сетевого интерфейса подключается к процессору через 2 порта FSL (FIFO); один главный FSL для записи данных для передачи и другой подчиненный FSL для чтения флагов синхронизации от других процессоров. Синхронизация FIFO имеет 16 слов (для 16 процессоров) и ширину 5 бит. В блоке сетевого интерфейса имеется счетчик 11 бит для измерения времени прохождения пакетов. Информация о синхронизации включается в заголовок, прикрепленный, когда пакеты входят в сеть, как показано на рисунке 3, и обрабатывается, когда пакеты поступают в сетевой интерфейс назначения.
Каждый входной порт имеет один буфер, построенный с использованием архитектуры двухпортового ОЗУ с 16 словами FIFO для поддержки максимум 16 блоков данных. Поскольку XY-маршрутизация свободна от взаимоблокировок, и мы не осуществляем приоритетную передачу пакетов, реализация виртуального канала бесполезна. Мы используем циклический арбитраж для выбора выходного порта, когда более одного входа запрашивают один и тот же выходной маршрут. Метод коммутации червоточины используется для передачи пакетов в NoC, поскольку он не требует большого буфера и имеет меньшую задержку. Для маршрутизации маршрутизация на основе детерминированных координат осуществляется с использованием координаты XYZ. Мы используем перемычку на основе мультиплексора, потому что она потребляет меньше площади, а также меньше энергии по сравнению с перемычкой матрицы. Каждый маршрутизатор имеет вертикальный порт для подключения к другому маршрутизатору на верхнем уровне с помощью микробампов.
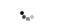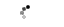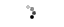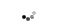
Рисунок 1: Архитектура маршрутизатора
Рисунок 2: Архитектура сетевого интерфейса
Рисунок 3: Формат пакета для NoC
Рисунок 4: Архитектура процессора Openfire
Внутривенно АРХИТЕКТУРА ПРОЦЕССОРА
Мы используем процессор с открытым исходным кодом для нашей реализации, который легко доступен, не тратя много времени на разработку нового процессора. Процессор Openfire, как показано на рисунке 4, загружен с Opencores.org [15]. Это клон Microblaze, который поддерживает Microblaze ISA и цепочку инструментов компилятора. Он поддерживает только аппаратный множитель. Хотя есть и другие доступные клоны Microblaze с открытым исходным кодом, мы выбрали Openfire, потому что он имеет порты FSL (порты FIFO), которые нам нужны для простой передачи данных и синхронизации между процессорами и NoC, а не с использованием более сложного интерфейса, такого как OCP и AXI, который требует сложной логики. , Процессор Openfire - это простой процессор, разработанный для конфигурируемых исследований процессоров [16]. Таким образом, из-за своей простоты он не потребует большой площади и, таким образом, может использоваться для разработки любого небольшого приложения для тестирования NoC в трехмерной архитектуре. Также мы используем только 4 КБ для инструкций и 4 КБ для памяти данных, чтобы ограничить область кристалла. Эти воспоминания генерируются с помощью компилятора памяти Artisan.
V. 3D 2 TIER 16PE MULTICORE
Наша архитектура, показанная на рисунке 6, состоит из двух уровней лицом к лицу. Каждый уровень имеет 8 процессоров, подключенных с использованием 4x2 NoC с использованием ячеистой сети. Соединение в каждом блоке плиток показано на рисунке 7. Соединение между уровнями достигается с помощью вертикальных портов каждого маршрутизатора. Общее количество ярусовых соединений составляет 594 соединения (35-битные данные при пересылке + 2 сигнала tx / rx + 2 сигнала JTAG для маршрутизатора с вертикальным портом в одном направлении) для всех 8 маршрутизаторов в одном уровне в двух направлениях. Соединения выполнены с 594 микронасосами, соединяющими два уровня лицом к лицу. Микроудары созданы из металлического 6 слоя обоих ярусов.
Синхронизация между процессорами осуществляется с использованием FSL, связанного с NoC. Процессоры взаимодействуют друг с другом через свою память данных. Процессор будет синхронизироваться перед доступом к своей памяти данных, ожидая слова тега в своем FSL, отправленного процессором записи. Это простая аппаратная реализация синхронизации для уменьшения площади матрицы.
В целом, наша конструкция вписывается в область матрицы 4,5 мм х 3,5 мм для каждого уровня. Целевая частота для функциональной работы составляет 166 МГц (тактовая частота 6 нс) и 10 МГц для тестовой работы. Схема нижнего уровня показана на рисунке 8, которая не сильно отличается от верхнего уровня (без блока контроллера JTAG).
Мы используем порт JTAG IEEE 1149.1 для интерфейса вне чипа. Контроллер JTAG расположен в нижней части матрицы и подключен к внешнему чипу с помощью TSV под площадкой ввода / вывода. Загрузка инструкции и памяти данных для каждого процессора также использует порт JTAG. Кроме того, память данных одного процессора (id 0) подключена снаружи, чтобы иметь быстрый доступ к результатам и иметь возможность предоставлять новые входные данные.
Технология TSV от Tezzaron под названием FaStack используется здесь только для плат ввода-вывода, изготовленных из вольфрама. Он имеет диаметр 1,2 мкм, шаг 5 мкм и глубину 6 мкм. Двухуровневый метод 3D-укладки основан на соединении пластин с пластинами посредством первого подхода, показанного на рис. 5. В качестве прокладки TSV используется оксид кремния для изоляции от кремниевой подложки. Пластина приклеивается перед утонением, и, таким образом, обработка пластин не требуется.
Процесс проектирования для проектирования 3D-архитектуры основан на инструментах 2D-EDA, как показано на рисунке 9. Важным этапом является спецификация, в которой мы определяем компоненты для каждого уровня. В этом проекте мы имеем одинаковую архитектуру для обоих уровней, за исключением блока контроллера JTAG. Каждый уровень может быть синтезирован и размещен и направлен отдельно и, таким образом, может быть выполнен параллельно. На этапе планирования этажа нам необходимо определить местоположение микронасосов для межуровневого соединения, чтобы мы могли подключить тот же сигнал к тому же выступу на другом уровне с помощью зеркалирования. После того, как проекты были направлены, мы можем интегрировать их в среду Virtuoso для подписи 3D DRC и 3D LVS перед отправкой в литейный цех.
VI. ЗАКЛЮЧЕНИЕ
Мы описали архитектуру нашего трехмерного мультипроцессора с архитектурой NoC, которая будет отправлена на изготовление через CMP. Архитектура NoC поддерживает блочную передачу данных для большой передачи данных между процессорами. Трехмерная архитектура состоит из 16 процессоров, разделенных на два уровня, соединенных с использованием ячеистой сети 4x2 NoC на каждом уровне. Реальные измерения приложений, работающих на 3D NoC, могут быть выполнены после изготовления чипа.
Рисунок 5: Двухуровневая технология Tezzaron
Рисунок 6: 2-уровневая мультипроцессорная архитектура
Рисунок 7: Блок-схема плитки
Рисунок 8: Маршрутный макет нижнего уровня
Рисунок 9: Ход проектирования
ССЫЛКА
[1] Р.С. Патти, Трехмерные интегральные схемы и будущее системной микросхемы, Материалы IEEE, 94 (2006), с. 1214-1224.
[2] W. Yun Jie, D. Houzet и S. Huet, Модель программирования и архитектура на основе NoC для потоковых приложений, Проектирование цифровых систем: архитектуры, методы и инструменты (DSD), 2010 г. 13-я конференция Euromicro, 2010 г., С. 393- 397.
[3] S. Evain, JP Diguet и D. Houzet, uspider: инструмент CAD для эффективного проектирования NoC, Norchip Conference, 2004. Proceedings, 2004, pp. 218-221.
[4] Л. Чжан, В. Фресс, М. Халид, Д. Хузет и А.-С. Исследование Legrand, оценка и проектирование пространства мультиплексированного NoC с временным разделением на FPGA для приложений анализа изображений, журнал EURASIP по встраиваемым системам, 2009 (2009).
[5] М. Х. Джаббар и О. Хаммами, Анализ производительности встроенного многоядерного процессора 16PE на основе NoC: влияние на конфигурацию процессора, международный дизайн и тестирование, IDT 2010, IEEE, Абу-Даби, 2010.
[6] В. Ф. Павлидис и Э. Г. Фридман, 3-D топологии для систем на основе микросхем, очень большая интеграция (VLSI), транзакции IEEE, 15 (2007), с. 1081-1090.
[7] К. Номура, К. Абэ, С. Фудзита, Ю. Куросава и А. Кагесима, Анализ производительности 3D-IC для многоядерных процессоров в технологиях CMOS до 65 нм, Схемы и системы (ISCAS), Труды 2010 IEEE Международный симпозиум, 2010, стр. 2876-2879.
[8] Б.С. Фееро и П.П. Панде, «Сети на чипе в трехмерной среде: оценка производительности», «Компьютеры», «Сделки IEEE», 58 (2009), с. 32-45.
[9] З. Тао, В. Куи, Ф. Йи, К. Ян, Л. Цунь, С. Бинг, Х. Цзин, С. Сяоди, Д. Лиан, Х. Юань, С. Сюй и Л. Юн -Долг, 3D SoC-дизайн для приложения H.264 со встроенным стеком DRAM, Конференция по интеграции 3D-систем (3DIC), 2010 IEEE International, 2010, стр. 1-6.
[10] М.Б. Хили, К. Атикульвонгсе, Р. Гоэль, М. М. Хоссейн, Д. Х. Ким, Л. Юнг-Джун, Д. Л. Льюис, Л. Цу-Вей, Л. Чанг, Дж. Муонгон, Б. Уэльет, М. Патхак , Х. Сане, С. Гуанхао, В. Донг Хюк, З. Синь, Г. Х. Лох, Х. С. Ли и Л. Сунг Кью, Проектирование и анализ 3D-MAPS: многоядерный 3D-процессор со стековой памятью, Специальные интегральные схемы Конференция (CICC), 2010 IEEE, 2010, стр. 1-4.
[11] Г. Ван дер Плас, П. Лимайе, И. Лой, А. Мерча, Х. Опринс, С. Торрегиани, С. Тийс, Д. Линтен, М. Стуччи, Г. Катти, Д. Веленис, В. Шерман, Б. Вандевельде, В. Симонс, И. Де Вольф, Р. Лаби, Д. Перри, С. Бронкерс, Н. Минас, М. Купак, В. Рюйторен, Дж. Ван Олмен, А. Фоммахаксай, М. де Поттер де тен Брок, А. Опдебек, М. Раковски, Б. Де Вахтер, М. Дехан, М. Нелис, Р. Агарвал, А. Пуллини, Ф. Ангиолини, Л. Бенини, В. Дехене, Й. Travaly, E. Beyne и P. Marchal, Проблемы проектирования и соображения для недорогой 3-D технологии TSV IC, твердотельные схемы, IEEE Journal of, 46 (2011), с. 293-307.
[12] И. Лой, П. Маршал, А. Пуллини и Л. Бенини, 3D NoCs - Объединение внутренней и внутрикристальной связи, схем и систем (ISCAS), Материалы Международного симпозиума IEEE 2010 г., 2010 г., с. 3337- 3340.
[13] С. Минео, Р. Дженкал, С. Меламед и У. Р. Дэвис, Межосевая сигнализация в трехмерных интегральных схемах, Конференция по заказным интегральным микросхемам, 2008. CICC 2008. IEEE, 2008, с. 655-658.
[14] Tezzaron Design Kit, CMP, http://cmp.imag.fr ,
[15] Процессорное ядро Openfire, ( http://opencores.org/project,openfire_core ).
[16] С. Крейвен, С. Паттерсон и П. Атанас, Конфигурируемые массивы мягких процессоров с использованием процессора OpenFire, Материалы 8-й ежегодной конференции по военным и аэрокосмическим программируемым логическим устройствам, MAPLD 2005, COSMIAC, Вашингтон, округ Колумбия, 2005.
Похожие
SOAP и REST: различение веб-сервисов на основе Java... ds/2019/12/ru-soap-i-rest-razlicenie-veb-servisov-na-osnove-java-1.jpg" alt="Установление связи между приложением и платформой - это основной принцип веб-сервисов"> Установление связи между приложением и платформой - это основной принцип веб-сервисов. Существуют сотни тысяч приложений, созданных на разных языках, для работы на разных платформах. Например, приложения на основе Java, работающие на платформах Linux, могут легко взаимодействовать с приложениями на основе PHP, работающими в Оценка сайтов или как оценить стоимость сайта?
В настоящее время считается, что сайт является тем же активом, что и недвижимость. Предприятия в балансе должны отображать веб-сайты как нематериальные активы, которые влияют на общую стоимость организации. Оказывается, оценка веб-сайта не простая задача. У тех, кто занимается продажами, есть свои любимые высказывания о ценности веб-сайтов: веб-сайт стоит столько, сколько клиент готов за него заплатить. Потенциальный покупатель, знакомый с рыночными условиями, может недооценивать Samsung Galaxy Tab S 8.4: на пути к совершенству
Samsung Galaxy Tab PRO 8.4, без сомнения, является одним из лучших планшетов на рынке, и кто знает, может быть, даже лучший маленький планшет с Android по разумной цене. Однако, как это бывает, не обошлось без изъянов. Является ли их лучшая версия Galaxy Tab S 8.4 лишенной их? Читайте также: Samsung Galaxy Tab Pro: 8.4 теперь новая 7 - паутина 36+ Bootstrap Gallery Темы и шаблоны
... основе HTML значительно облегчило задачу пользователям Интернета. С этими загрузочные шаблоны веб-страницы организованы в чистой и нишевой манере. Они могут быть легко ориентированы. Эта функция делает их чрезвычайно удобными для пользователя. Существуют варианты включения изображений, шрифтов, а также цветовых эффектов при загрузке на веб-сайты и страницы в соответствии с потребностями. Такой шаблон в Лишенной их?